Editor's Note:
New research was published on the validation of a real-world mortality variable. Learn more about the research
Today more than ever, researchers are turning to real-world data in order to shed light on questions throughout the oncology therapeutic lifecycle — impacting everything from translational research and trial design through regulatory approval. The stakes are high and researchers are obliged to scrutinize the source data to assess its fitness for use in such applications. It’s this scrutiny that leads us to some striking insights about the completeness of mortality information in real-world data.
This story starts at the point of care. In routine care, patient data is collected as necessary to support the treatment of a patient. If a CBC is warranted, blood is drawn and the test results become part of the electronic health record (EHR). If a scan is warranted, it’s performed and documented. If a patient with advanced cancer dies, what is warranted is perhaps a phone call to the family, or a condolence letter. But aside from that, the electronic health record demands no attention – particularly in an outpatient setting.
And we find this reality reflected in our analyses: structured mortality data in the EHR typically exhibit sensitivity levels around 65%. To be clear, this means that approximately 35% of actual deaths are missing from structured EHR fields.
Approximately 35% of actual deaths are missing from structured EHR fields.
Where to look for missing deaths
The risks of performing naive outcome analyses on EHR-derived real-world data are not to be underestimated. If you depend on accurate real-world overall survival (rwOS) estimates this is something you need to pay attention to: real-world data (RWD) companies must address the issue of low mortality sensitivity in order for the data to be considered fit for use.
One way that the sensitivity of mortality in RWD can be addressed is to look beyond structured data in the EHR and supplement with additional sources of death data — forming a composite variable. When evaluating the reliability of a composite mortality variable, researchers should first look at the individual sources of death data across several key areas. These areas, namely completeness, recency, accuracy and accessibility, all can have downstream impacts on the reliability of survival analyses.
There are a few common sources of this information outside of the EHR, each with their own caveats and characteristics:
Data Source #1: National Death Index
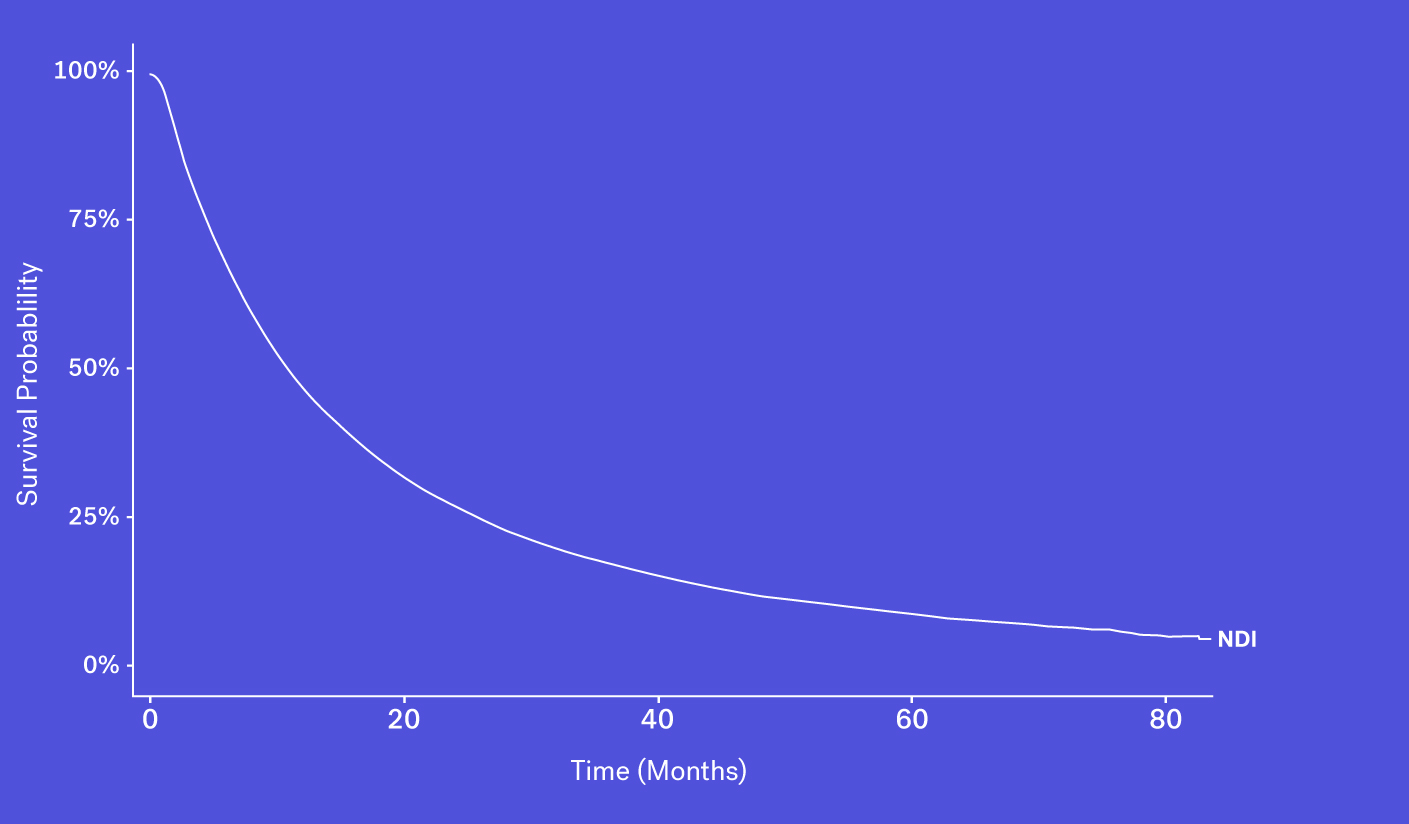
The National Death Index (NDI), which obtains its information via state Vital Statistics offices, is often considered the gold standard for US mortality data, though this database faces a number of challenges and limitations.
To start, obtaining access can be difficult, as acquiring the file is both time consuming and costly. And while data can be made available in certain instances, the NDI can face up to a 22-month lag before deaths are available to researchers. This is especially problematic in a field like oncology where the standard of care evolves quickly and recency is critical to ensure accurate and contemporary analyses. Finally, as the NDI cannot be used commercially, RWD providers are unable to package NDI data as part of their data products.
Data Source #2: Social Security Death Index
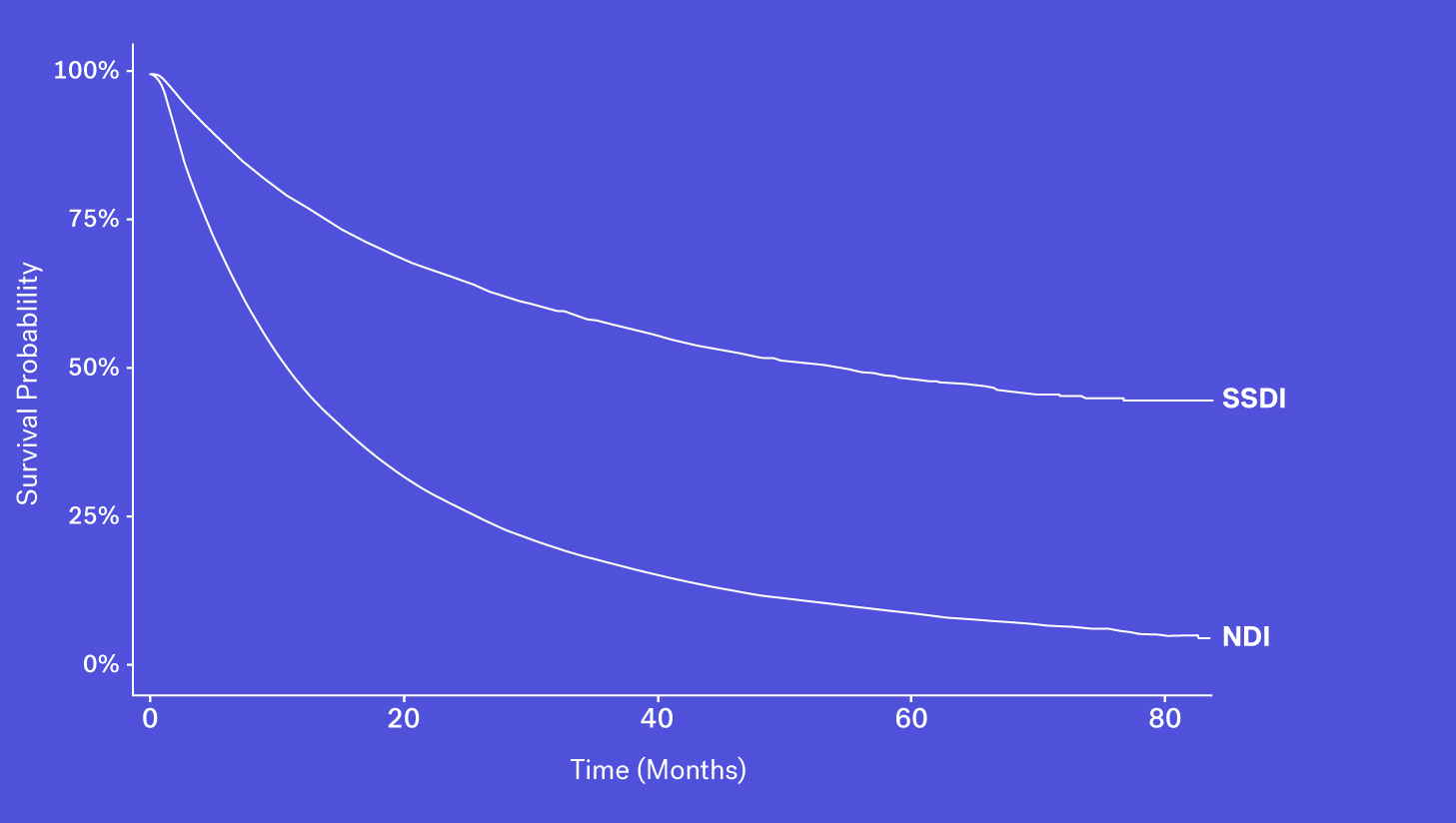
Since 2011, the Social Security Death Index (SSDI), a national database of U.S. deaths reported to the Social Security Administration, has been declining in sensitivity compared to the NDI. Historically, the SSDI was seen as an accurate source of mortality data by researchers. It had a fairly short lag in reporting (around 4-6 months) and included data on patients who died both at home and in a healthcare facility (Levin, et al., 2018). Things changed in 2011 amid concerns of the database being used for fraud and identity theft, and substantial changes were made to the SSDI which resulted in the abrupt removal of approximately four million historical records. Additionally, each subsequent year has seen one million fewer records added than before this change.
As a result, while it still contains valuable death data, it is not fit for use as a sole source of mortality information for survival analyses.
Data Source #3: Obituary Data Sources
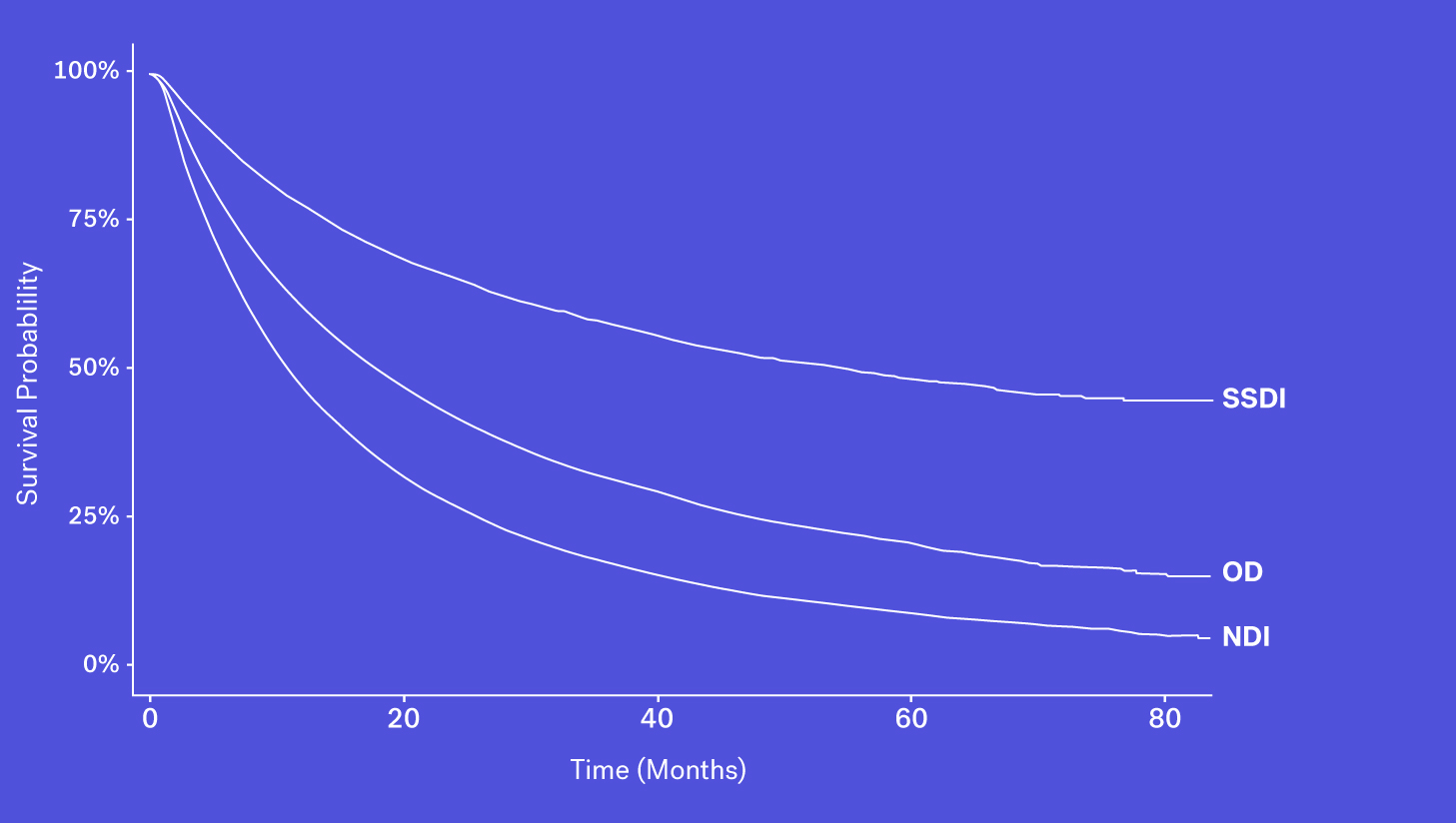
A number of obituary data sources are available for researchers to better understand survival rates for a given population. These datasets, however, may be prone to missingness, especially for certain types of patients who may be less likely to have an obituary. Despite that, obituaries, when combined with other sources, can help to complete the picture.
Data Source #4: Structured EHR Data Sources
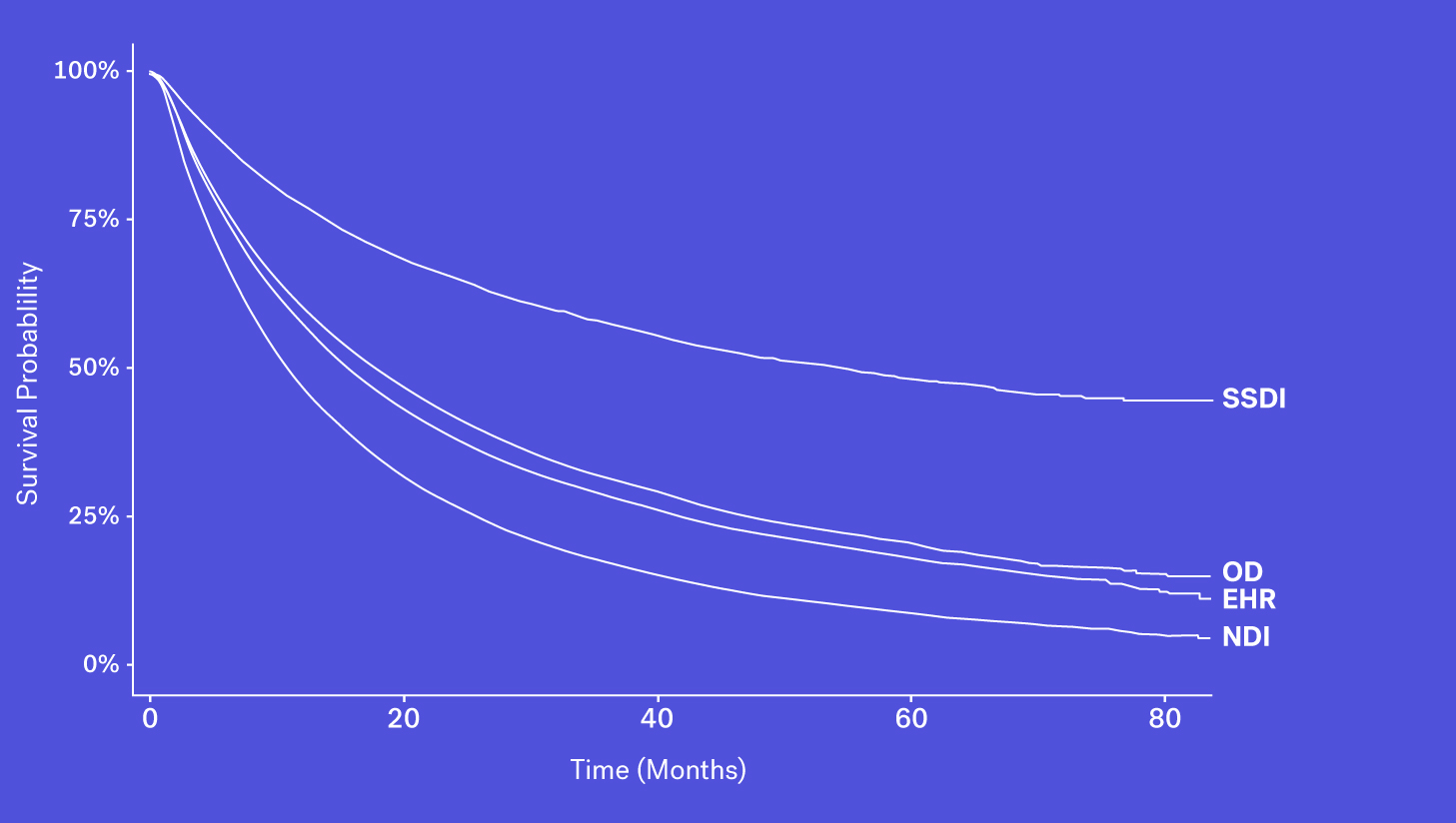
Mortality data may be captured and entered into structured data fields as part of routine clinical care. However, while easy to access, we see that mortality information from structured EHR fields alone can be quite incomplete. This could be due a patient transferring their care, moving to hospice or simply because inputting that information isn’t required in EHRs.
Recap: Bringing it all together
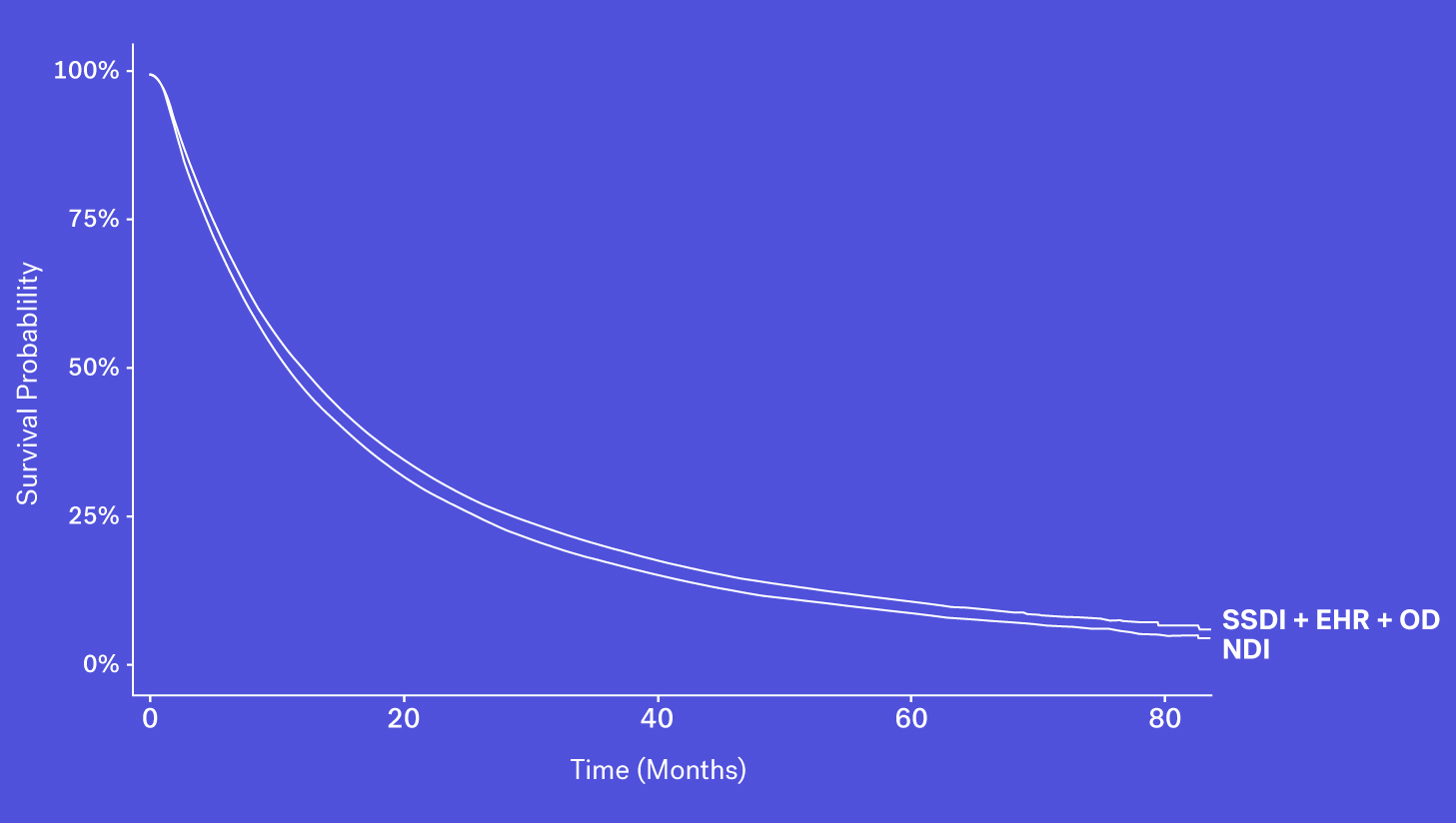
When looking at these data sources through the lens of completeness, recency and accessibility, each source has its own benefits and drawbacks. While the SSDI is largely accessible and has a higher level of recency, due to updated regulations it suffers from lower levels of completeness. The NDI is assumed to be nearly complete but has poorer recency and limitations on its use. Obituary data is timely but is subject to completeness limitations. Additionally, while structured death data in the EHR may be incomplete, one can supplement that data with additional information contained in the EHR – unstructured documentation (e.g., condolence letters, death certificates) – to further increase the sensitivity of the variable.
Each of these data sources represents a piece of the puzzle and with the right techniques, these data sources can be coalesced to form a more complete picture of survival.
Why this matters
To help illustrate why this matters, let’s consider a few use-cases for real-world data:
Trial design
A critical input for ascertaining a target sample size in an RCT is understanding the event rate, such as the number of deaths expected to accrue during follow-up, for both the treatment cohort and the control group. In today’s oncology landscape however, that control group tends to be a moving target as standards of care continue to rapidly evolve. For that reason, the recency of real-world data is appealing – it’s your best snapshot of contemporary treatment patterns and outcomes.
Now, if those data aren’t reflecting an accurate picture of mortality – in this case having low sensitivity (i.e. representing fewer death events), researchers may then come to the conclusion that they need to recruit more patients to demonstrate a survival benefit that is statistically meaningful, leading to longer recruitment times for trials, substantially higher costs, reduced feasibility and potentially a no-go decision.
Comparing treatment effects in RWD vs. clinical trials
Researchers who include real-world evidence to support comparative effectiveness research, particularly with regards to a single-arm trial, must seek (and be able to cite!) proper assessments of key endpoints, such as rwOS. Without demonstrating that the endpoint has been assessed with appropriate analytical techniques, companies risk improper comparisons which are magnified in a regulatory setting.
In fact, when conducting survival analyses with incomplete mortality data, researchers are at risk of minimizing the observed benefit of a therapy as seen in a trial setting compared to a real-world setting. In order to understand the impact of missing death data, researchers in a 2019 study (Carrigan, et al., 2019) simulated external control arm analyses comparing aNSCLC patients on two different treatments. They simulated various sensitivities for the real-world mortality EHR-derived variable for the control arm, and used death dates from the NDI for the experimental arm. When the researchers simulated a sensitivity of 63.4% for the control arm (meaning approximately 27% of deaths were missing) they calculated a hazard ratio (HR) of 1.21 for the experimental arm compared to the control arm. This was substantially higher than, and in the opposite direction of, the HR of the analyses that used the NDI for both the experimental and control arms, which was 0.90. In contrast, when the real-world mortality variable had a sensitivity of 90.6%, the HR was 0.94.
Long-term survival extrapolation
Access discussions (particularly outside of the US) focus on evaluating the clinical benefits of a therapy over an extended period of time. Due to the shorter length of randomized clinical trials and a need to understand longer-term effects of therapies, a common analysis included in Health Technology Assessments (HTAs) is the 5-year survival extrapolation.
While there are many extrapolation models, each with a nuanced predictive capacity, real-world data can help to substantiate the choice of extrapolation methods, providing additional evidence in support of a 5-year survival estimate. Of course, performing these extrapolations with incomplete mortality information risks projections that may overestimate survival to an extent to which health authorities may deem it implausible.
The bottom line
Understanding the ways in which incomplete survival data can lead experts astray is essential to the successful application of real-world data. Certain techniques, such as the development of a composite mortality variable that demonstrates a high degree of sensitivity and specificity, are proving worthy in the effort to paint an accurate and timely representation of patient survival.
Before you consider the use of RWD, start with these questions:
-
What measures have been taken to assess the sensitivity and specificity of the real-world death data?
-
Is the reference dataset chosen for benchmarking death data appropriate for calculating validity metrics?
-
What solutions have been implemented to address missingness in the dataset?
-
What research can be cited to characterize the sensitivity of the real-world mortality dataset?
Acknowledgements
Kellie Jo Ciofalo, Director, Strategic Opertations
Aracelis Torres, Director, Quantitative Sciences
Nicole Mahoney, Senior Director, Regulatory Policy
Nate Nussbaum, Senior Medical Director
Sandy Griffith, Principal Methodologist, Quantitative Sciences
Neal Meropol, Vice President, Head of Medical and Scientific Affairs
Qianyi Zhang, Senior Quantitative Data Analyst
Anala Gossai, Quantitative Scientist